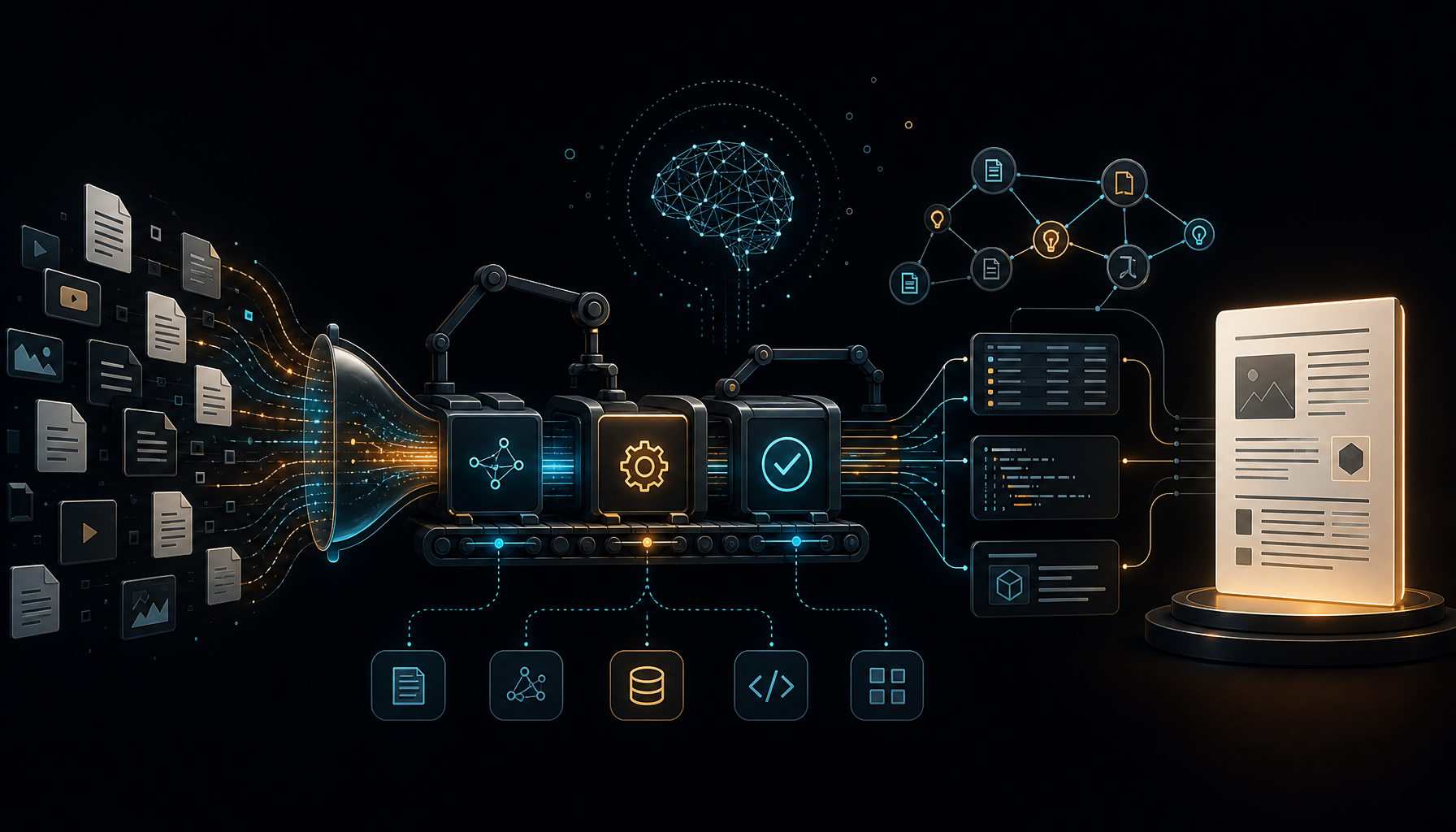
一、知识管理的真实痛点
做技术的同学大概都经历过这些时刻:
- 对接了一个平台,对方丢过来一份上百行的 Word 接口文档,字段名是拼音缩写,描述是口语大白话。你想把它整理成团队可用的参考,但对着那个 600 行的表格实在提不起劲。
- 看到一个不错的 GitHub 项目,README 写得很全,但看完还是说不清它和竞品的区别。想做一份内部的技术选型笔记,又觉得重复搬运低价值。
- 微信上收藏了一篇好文章,想存档到自己的知识库里加上批注和拓展,但复制粘贴过来格式一团乱,配图还要自己重做。
- 开了个技术评审会,白板上画了架构图,拍了照就扔在相册里,两周后翻出来已经忘了当时的决策逻辑。
这些痛点的共性是什么?信息进来了,但被卡在”处理”这一步。 大脑知道这些信息有价值,手却说”整理起来太累了”。
结果就是:信息不停涌入,知识库却长期荒芜。
二、理想的知识处理管线
如果把这个流程抽象成一条管线,它应该长这样:
1 | INPUT PROCESS OUTPUT |
关键设计原则:
- 多样化输入,统一输出——无论来源是什么格式,最终都变成同一套高质量 Markdown + PNG 的文章结构
- AI 不只写文字,还画图——封面、架构图、时序图全部由 AI 根据文章内容自动生成,风格统一
- 零手动操作——管线一旦触发,从提取到发布全程自动完成
三、实现方案
整个系统围绕 Hexo 静态博客构建,核心是一套工具链 + 一个 Agent 编排层。
3.1 静态博客底座
选用 Hexo + 自定义主题 的方案而非 WordPress 或 Notion 发布,有几个原因:
- 纯静态:HTML 文件扔进 Nginx 即可,零运维成本
- Markdown 原生:文章源码就是
.md文件,天然可版本化(Git) - 完全可控:主题是自定义的 Apple-inspired 设计,每个像素都能改
部署在 1Panel + OpenResty 上,hexo generate 生成静态文件后直接 rsync 到 Web 目录。
3.2 AI 图片生成工具
自建了一个命令行工具,接收自然语言描述,调用 GPT Image 2 生成配图:
1 | # 为文章自动生成封面(读取 front matter 的标题和分类) |
它会根据文章分类自动匹配视觉风格——“技术方案”用琥珀+青蓝配色、”软件选型”用青蓝+橙色、”平台接口”用电蓝+紫色,保证整个博客的封面风格统一。
3.3 知识处理管线
管线的核心逻辑只有 5 步,对所有输入源通用:
Step 1 提取:用对应的工具把原始内容拉出来
.docx→ ZIP 解压 + XML 解析(Python 标准库,零依赖)- URL / 微信文章 → web_extract 或浏览器提取
- GitHub →
git clone --depth 1+ 读关键文件
Step 2 分析:判断文章应该归到哪个分类、打什么标签、自然段落怎么切、配图插在哪里
Step 3 撰写:核心原则——绝不直接粘贴原文。必须做结构化转换:
- 平铺文字 → 分层章节
- 逐行罗列 → Markdown 表格
- 内联示例 →
```json代码块 - 口语措辞 → 专业技术中文
- 散落修改记录 → 整合修订表
Step 4 配图:封面 + 架构图 + 时序图,三张图并行生成,总耗时约 1 分钟
Step 5 发布:hexo generate → rsync → git push

3.4 支持的输入场景
| 输入类型 | 触发方式 | 典型产出 |
|---|---|---|
| 接口文档 (.docx/.pdf) | 上传文件 | 专业 API 技术规范,含参数表、示例 JSON、错误码对照 |
| GitHub 仓库 | 发 Repo URL | 技术架构分析:模块结构、技术栈、部署方式 |
| 微信/博客文章 | 发文章链接 | 深度拓展版(加背景、加实践、加对比)或精炼摘要版 |
| 技术调研需求 | 说”研究一下 X” | 多源交叉验证的综述文章,附来源链接 |
| 会议纪要/笔记 | 贴原始记录 | 结构化决议 + 行动项 + 技术细节 |
| 代码库分析 | 指本地目录 | 模块依赖图 + 数据流 + 配置说明 |
| 随口一个主题 | 说”写一篇关于 X” | 从领域知识直接生成 |
四、实际收益
4.1 效率对比
以一次接口文档处理为例——一份 645 行的 Word 文档,包含语音通知 API 的参数表、事件码、修改记录:
| 环节 | 纯手工 | 使用管线 |
|---|---|---|
| 阅读并理解文档 | 20 分钟 | 自动 |
| 重新组织结构 | 40 分钟 | 自动 |
| 写 Markdown + 表格 | 60 分钟 | 自动 |
| 画封面 + 架构图 + 时序图 | 90 分钟(找素材+PS) | 1 分钟(并行生成) |
| 校对 + 发布 | 15 分钟 | 5 分钟 |
| 合计 | ~3.5 小时 | ~5 分钟 |
产出的文章质量反而更高——统一的前端格式、语法高亮的 JSON 示例、紧凑的双栏错误码表、风格一致的 3 张 AI 插图。
4.2 知识资产化
最大的变化不是省了多少时间,而是知识从”脑子里”或”聊天记录里”变成了可检索、可引用、可复用的资产:
- 可检索:Hexo 生成全文搜索 JSON,站内任意关键词秒出结果
- 可引用:每篇文章有固定 URL(
/posts/<slug>/),发给同事就是一个链接 - 可复用:下次对接同一个平台,不用再翻聊天记录找当时的坑——直接打开对应文章
- 可迭代:文章源码在 GitHub,修改一个 typo 只需要改 Markdown 然后
git push
4.3 从”收藏等于学会”到”发布等于消化”
这条管线改变了信息处理的心理门槛。以前看到一篇好文章,”收藏”是终点。现在收藏之后还有一条清晰的路——提炼、重组、配上自己的理解和插图、发布到自己的知识库。
结果是:每处理一次信息,知识库就多一篇文章,而不是多一个书签。
五、总结
这条管线解决的不是”AI 能不能写文章”的问题——AI 写文章早就不是新闻。它解决的是更实际的问题:
怎么让”把这件事整理成文档”这件事,从 3 小时的抗拒变成 5 分钟的随手操作。
当一个技术文档从接收到发布上线的时间小于泡一杯咖啡的时间,知识库就不再是需要刻意维护的东西——它变成了工作流的自然产出。

