
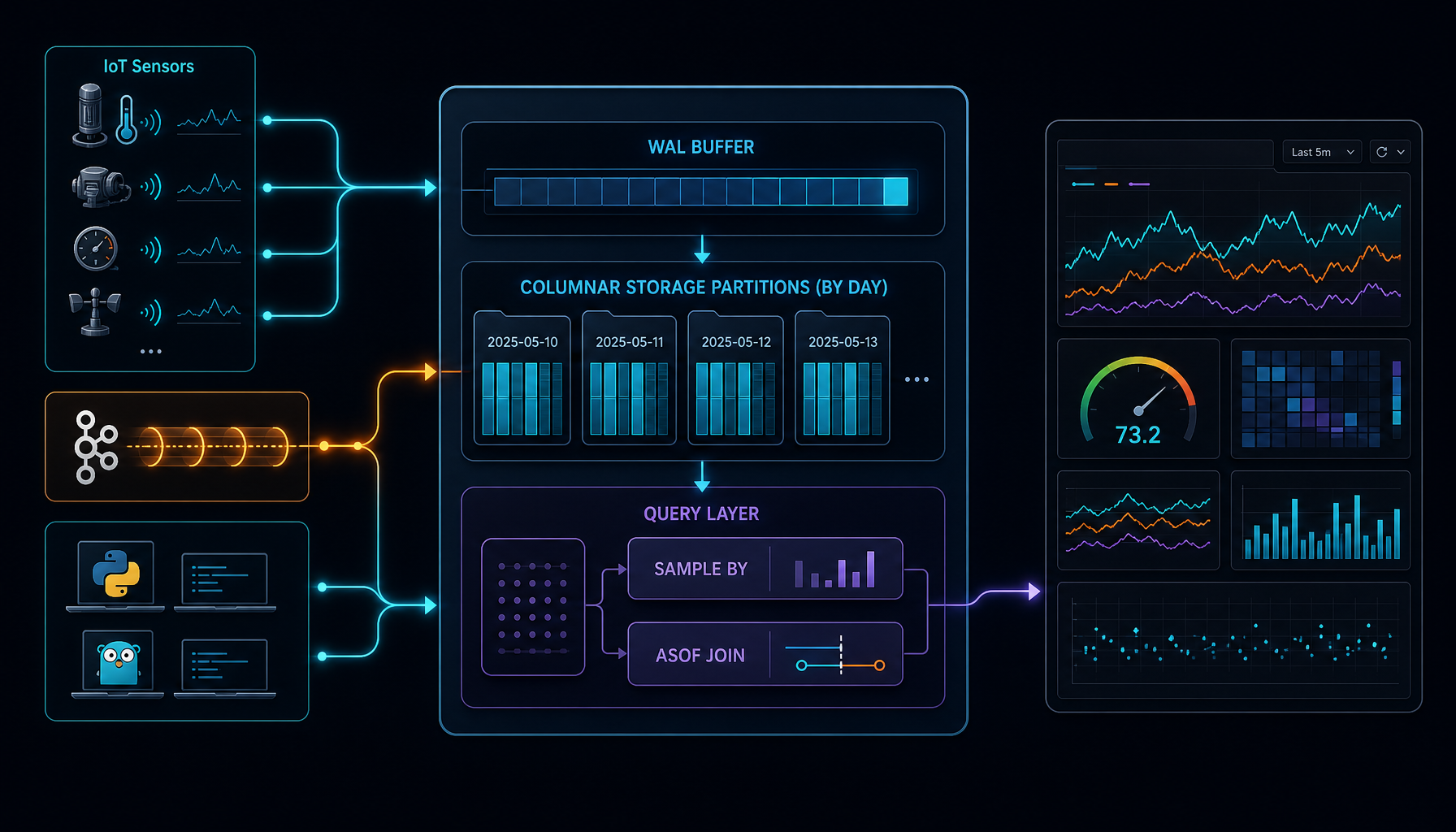
一、为什么选 QuestDB
QuestDB 是一个专为时序场景从头设计的开源数据库(Apache 2.0),核心引擎用 零 GC 的 Java + C++ 实现,企业版额外包含 Rust 组件。与在通用数据库上「套一层时序扩展」的方案不同,QuestDB 的每一层都是为时间序列数据优化的。
与竞品的核心差异
| 特性 | QuestDB | InfluxDB | TimescaleDB | ClickHouse |
|---|---|---|---|---|
| 存储模型 | 列式 + 时间分区 | 列式 (TSM) | PostgreSQL + hypertable | 列式 + 分区 |
| 查询语言 | SQL + 时序扩展 | InfluxQL / Flux | SQL | SQL |
| 写入协议 | ILP / PGwire / HTTP | ILP | PGwire / COPY | Native / HTTP |
| 单机吞吐 | 百万行/秒 | 数十万行/秒 | 十万行/秒级 | 百万行/秒 |
| 部署复杂度 | docker run 一条命令 |
配置较多 | 依赖 PG 生态 | 配置复杂 |
| 开源协议 | Apache 2.0 | MIT | TSL | Apache 2.0 |
在 QuestDB vs InfluxDB 的官方基准测试 中,同硬件条件下 QuestDB 写入吞吐是 InfluxDB 的 3–5 倍,查询延迟低一个数量级。
二、快速部署
Docker 部署(推荐)
1 | docker run -d \ |
三个端口的用途:
| 端口 | 协议 | 用途 |
|---|---|---|
| 9000 | HTTP | Web Console、REST API、ILP 写入、CSV 导入 |
| 8812 | PostgreSQL Wire | 程序化查询(读写),任何 PG 客户端可直接连接 |
| 9009 | PostgreSQL Wire | 只读查询,适合 Grafana 等可视化工具 |
启动后访问 http://localhost:9000 即进入 Web Console,可以直接写 SQL 和看结果。
Docker Compose(生产推荐)
1 | version: '3.8' |
生产环境关键配置 (server.conf)
1 | # 共享线程数 — 设为 CPU 核数 |
三、数据模型与时序 SQL
Designated Timestamp(指定时间戳)
QuestDB 每张表必须有一个 designated timestamp,这是时序查询优化的基础:
1 | CREATE TABLE sensor_data ( |
TIMESTAMP(ts):指定ts为时序列,所有SAMPLE BY、LATEST ON等时序函数依赖它PARTITION BY DAY:按天分区,数据按时间物理隔离,删除过期分区是 O(1) 操作WAL:启用预写日志(v8.0+),保证 crash 安全SYMBOL:QuestDB 特有的低基数字符串类型,内部用整数 ID 映射,比VARCHAR快一个数量级
时序 SQL 扩展
QuestDB 的 SQL 在标准 SQL 之上扩展了关键的时序操作:
SAMPLE BY — 时间窗口聚合
1 | SELECT |
SAMPLE BY 自动按时间分组,比 GROUP BY + 手动 trunc 更简洁高效,结果集的时间戳自动对齐到窗口边界。
LATEST ON — 最新值快照
1 | SELECT * |
返回每个设备的最新一条记录。在设备监控场景中,「所有设备的当前状态」是最常见的查询,LATEST ON 专门为此优化。
ASOF JOIN — 时间对齐连接
1 | SELECT |
ASOF JOIN 按最接近的时间戳关联两条记录,是金融数据处理的标准操作。在通用数据库中这需要窗口函数加多步子查询,QuestDB 原生支持。
WHERE 时间范围 — 分区裁剪
1 | -- 精确一天 |
WHERE timestamp IN 语法是 QuestDB 特有的,背后直接触发分区裁剪——只扫描涉及的分区,跳过其余所有。
四、数据写入实战
InfluxDB Line Protocol(ILP)— 高频写入首选
ILP 是文本协议,一行一条记录,无 schema 开销:
1 | sensor_data,device_id=TH-001 temperature=23.5,humidity=68.2 1718236800000000000 |
Python 写入示例:
1 | from questdb.ingress import Sender |
对于批量采集场景,每 flush() 前缓冲几千行可获得最佳吞吐。
PostgreSQL Wire Protocol 写入
直接用 PostgreSQL 客户端连接端口 8812:
1 | import psycopg2 |
要注意 QuestDB 不完全兼容所有 PG 语法——它不支持 UPDATE 和 DELETE(不可变设计),建议批量 INSERT。
HTTP API 写入
适合轻量场景或无客户端语言:
1 | curl -X POST "http://localhost:9000/imp" \ |
Kafka → QuestDB 流式接入
生产环境推荐通过 Kafka Connect 或直接使用 QuestDB 的 ILP over TCP 从 Kafka Consumer 写入:
1 | # Kafka Connect 配置要点 |
五、可视化与监控
Grafana 集成
QuestDB 提供原生 Grafana 插件,通过 PGwire(端口 8812)连接:
- Grafana → Administration → Plugins → 搜索
QuestDB - 安装后新增 Data Source,URL 填
localhost:8812 - 查询面板直接用 SQL:
1 | SELECT |

常用监控 SQL
1 | -- 每台设备最近 5 分钟的平均温度 |
六、生产环境注意事项
硬件规划
- 内存:QuestDB 使用内存映射文件,建议内存 ≥ 热数据总量的 20%
- 磁盘:NVMe SSD 最优,避免网络存储(NFS/EBS 弹性盘延迟不稳定)
- CPU:4 核以上,ILP 写入和查询各自独立线程池
分区策略
1 | -- 高频传感器数据(日千万级行)→ 按天分区 |
分区粒度过细会增加文件数,过粗则影响范围查询性能。按数据密度选择。
数据保留与清理
1 | -- 删除 30 天前的分区(O(1) 操作) |
备份
1 | # 导出全表 |
七、适合你的场景
如果你的项目符合以下特征,QuestDB 是非常匹配的选择:
- ✅ 每天百万级以上时序数据写入
- ✅ 需要 SQL 而不是学习新的查询语言
- ✅ 按时间范围做聚合分析(
SAMPLE BY/LATEST ON) - ✅ 用 Grafana 做仪表盘,想直接用 SQL 而不是 Flux
- ✅ 小团队运维,不想管复杂的分布式系统
- ✅ 部署在 Docker 或裸机,对资源敏感
不太适合的场景:
- ❌ 需要频繁
UPDATE/DELETE单行(不可变设计) - ❌ 需要分布式横向扩展(QuestDB 目前主打单机高性能,企业版支持多节点)
- ❌ 重度依赖 PostgreSQL 生态的扩展插件
八、总结
QuestDB 的高性能来自「从头为时序场景设计」:列式存储 + 时间分区 + SIMD 向量化执行 + ILP 协议。它不是给 PostgreSQL 加了个插件,也不是套了一层 SQL 壳的 NoSQL——它本身就是为百万行/秒写入和毫秒级查询而生的引擎。
对于 IoT 设备采集、实时监控、金融行情这三大场景,用一条 docker run 就能拥有不输商业数据库的性能,且 SQL 零学习成本,这正是它最吸引人的地方。